🚀 Building an AI App Using Local LLMs – Architecture & Fundamentals (Part 1)
Tue Jan 13 2026
From Zero to AI App — Understanding Architecture, Local LLMs & AI Engineering Fundamentals
🧠 Post Series Overview
This is a 5-part hands-on AI engineering blog series where we build a production‑style AI Wish Generator application powered entirely by a local LLM (LLaMA) — without OpenAI APIs, without cloud dependency, and without vendor lock‑in.
Each post focuses on a core engineering layer used in real-world AI systems.
📘 Series Breakdown
| Part | Topic
| ---------- | ---------------------------------------------------------------
| Part 1 | Architecture, local LLMs & AI engineering fundamentals
| Part 2 | Backend development using Python + FastAPI + prompt engineering
| Part 3 | Modern frontend using Next.js (SPA, responsive design)
| Part 4 | Dockerizing local LLMs & preparing for cloud deployment
| Part 5 | AI Engineering Lessons from Building a Local LLM App
🧩 Why Build a Demo App Like This?
Before jumping into tools and frameworks, let’s address the most important question.
Why should an AI engineer build such demo applications?
Because AI engineering is not about calling an LLM API.
It is about understanding:
- How prompts control behavior
- How responses flow through systems
- How latency, streaming and UX affect perception
- How models integrate with backend services
- How deployment choices affect cost and scalability
A simple demo app — when designed correctly — becomes a miniature version of real AI platforms like ChatGPT, Claude, or Perplexity.
🎯 What Are We Building?
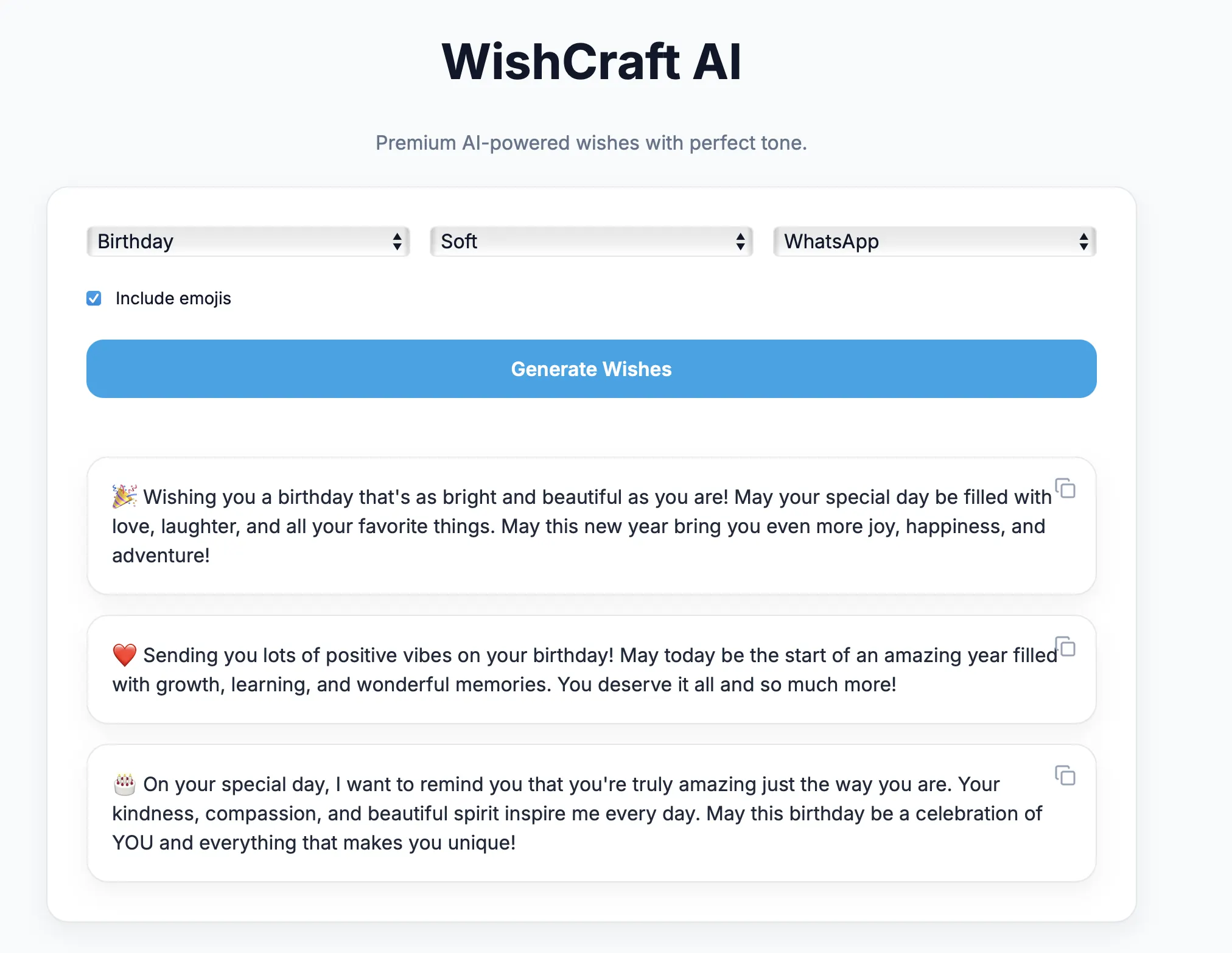
We are building an AI Wish Generator Application that:
- Runs LLaMA locally using Ollama
- Accepts structured user input
- Applies advanced prompt engineering
- Generates tone‑aware, platform‑aware wishes
- Supports WhatsApp, Instagram, Facebook & Slack
- Uses platform‑specific emoticons
- Works as a single-page application (SPA)
- Can be containerized and shipped anywhere
Example Output
Congratulations on your new role :tada:
Wishing you success and exciting challenges ahead.
Looking forward to seeing your impact.
No cloud LLMs. No paid APIs. 100% local inference.
🧠 Understanding Local LLMs
What is a Local LLM?
A local LLM is a large language model that runs:
- On your laptop
- On your server
- Inside Docker
- Without internet dependency
Examples:
- LLaMA 3
- Mistral
- Phi
- Gemma
In our project we use:
LLaMA 3 via Ollama
🦙 Why Ollama?
Ollama provides:
- Local model runtime
- REST API interface
- Streaming token support
- Model version management
- Extremely simple setup
ollama pull llama3
ollama run llama3
Behind the scenes:
Your App → HTTP API → Ollama → LLaMA Model
This abstraction allows us to treat LLMs just like any other backend service.
🧱 High‑Level Architecture
┌────────────────────┐
│ Next.js Frontend │
│ (SPA UI) │
└─────────▲──────────┘
│ REST API
┌─────────┴──────────┐
│ FastAPI Backend │
│ Prompt Engine │
│ Validation Layer │
└─────────▲──────────┘
│ HTTP
┌─────────┴──────────┐
│ Ollama Runtime │
│ Local LLaMA LLM │
└────────────────────┘
🔍 Where AI Engineering Actually Happens
Many people think AI engineering is just this:
response = llm(prompt)
That’s only 5% of the job.
The real engineering lies in:
- Prompt architecture
- Output constraints
- Emotional safety
- Platform formatting rules
- Streaming token handling
- UI synchronization
- Container orchestration
This project touches every one of them.
🧠 Prompt Engineering as a System
Our prompts are not plain text.
They contain:
- Output contracts
- Structural rules
- Emoji governance
- Platform‑specific formatting
- Tone constraints
- Safety guardrails
Example:
Slack:
- Use :tada: :rocket: :thumbsup:
- Never use Unicode emojis
Instagram:
- Use aesthetic emojis ✨🌸💫
WhatsApp:
- Friendly expressive emojis 😊🎉
This transforms the LLM from a chatbot into a deterministic text engine.
⚙️ Why This App Is Perfect for Learning AI Engineering
This demo teaches you:
- ✅ LLM orchestration
- ✅ Prompt governance
- ✅ API design for AI
- ✅ Frontend AI UX
- ✅ Streaming vs blocking responses
- ✅ Containerization of models
- ✅ Deployment‑ready architecture
All using open‑source tools.
🔥 Real‑World Relevance
This same architecture pattern is used in:
- AI customer support bots
- Resume generators
- Email assistants
- HR copilots
- Knowledge agents
- RAG systems
- Autonomous workflows
If you understand this demo app deeply — you understand AI system design.
📦 Tech Stack Summary
| Layer | Technology |
| ------------ | ------------------- |
| LLM | LLaMA 3 |
| Runtime | Ollama |
| Backend | Python + FastAPI |
| Prompt Layer | Custom prompt rules |
| Frontend | Next.js 14 |
| Styling | Tailwind CSS |
| Deployment | Docker |
🔜 What’s Coming in Part 2
In the next post we will deep dive into:
- Designing the FastAPI backend
- Request/response contracts
- Prompt engineering patterns
- Guardrails for emotional safety
- Multi‑option wish generation
- Platform‑aware emoticons
👉 Part 2: Building the Backend & Prompt Intelligence Engine
✨ Final Thoughts
This series is not about building a toy app.
It’s about learning how real AI systems are engineered — step by step — using tools you can fully control.
If you can build this application confidently:
You are already thinking like an AI engineer.