Retrieval-Augmented Generation and Core Algorithms
Mon Jan 12 2026
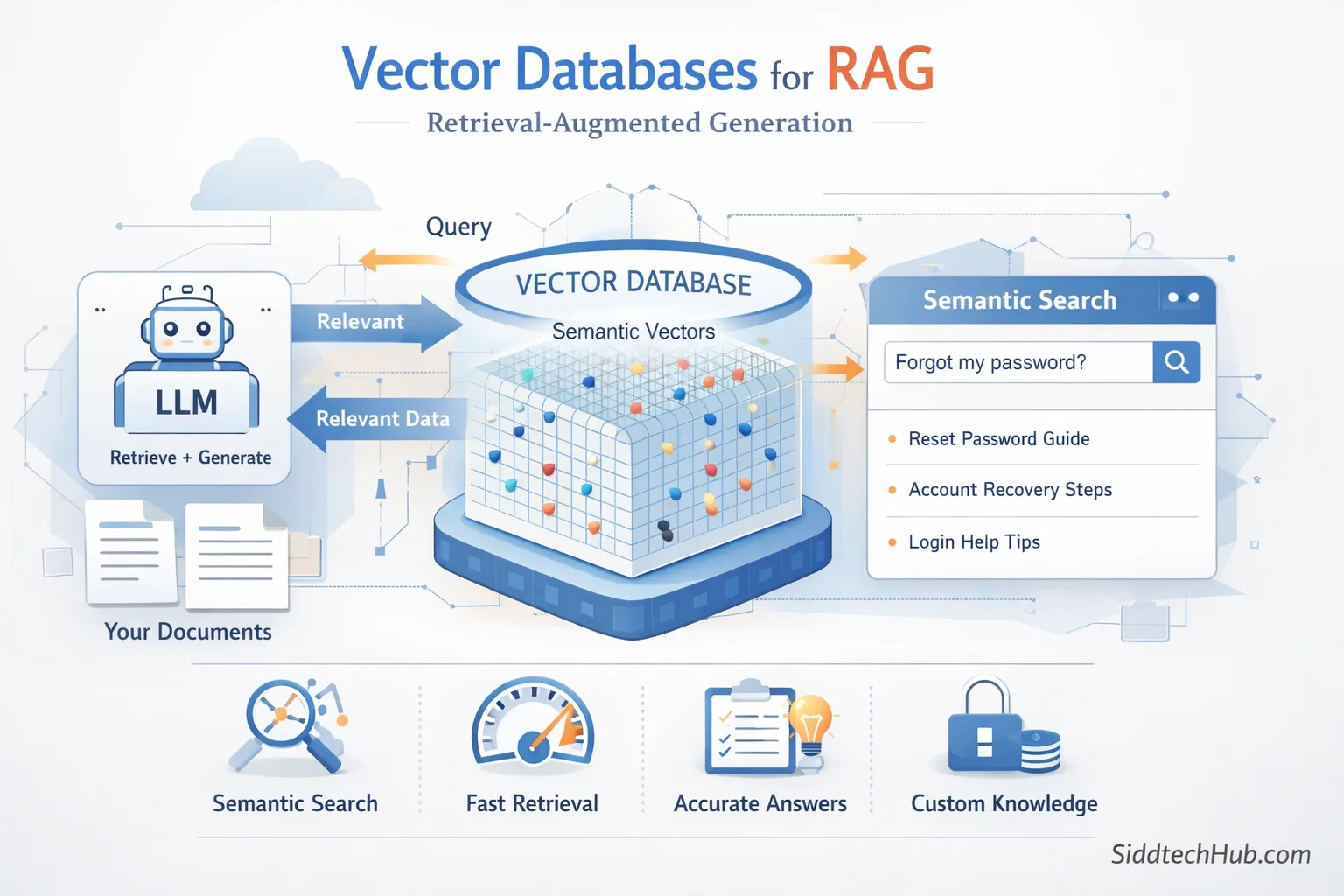
RAG Architecture Explained
Retrieval-Augmented Generation (RAG) is one of the most important architectural patterns in modern AI systems.
It enables Large Language Models (LLMs) to answer questions using external knowledge instead of relying only on their training data.
RAG is widely used in:
- Enterprise AI assistants
- Chatbots over private documents
- Knowledge-based search systems
- AI copilots and agents
This blog explains RAG architecture in a simple and structured way and covers the most widely used algorithms behind RAG systems.
What is Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation is an architecture where:
- Relevant documents are retrieved from an external knowledge source
- The retrieved information is injected into the prompt
- The LLM generates a grounded and factual answer
Instead of asking the model to guess, RAG allows the model to reason using real data.
Why RAG is Needed
LLMs have several limitations:
- They cannot access private data
- They hallucinate when knowledge is missing
- Their training data becomes outdated
- Fine-tuning is expensive and slow
RAG solves these problems by combining retrieval and generation.
High-Level RAG Architecture
User Query
↓
Query Embedding
↓
Vector Search
↓
Top-K Relevant Chunks
↓
Prompt Construction
↓
LLM Response
Core Components of RAG Architecture
Data Source
Data can come from multiple sources:
- PDF documents
- Word files
- Web pages
- Databases
- APIs
- Internal documentation
Document Loader
Document loaders read raw data and convert it into plain text.
Examples include:
- PDF parsers
- HTML scrapers
- Database connectors
- API loaders
Text Chunking
Documents are split into smaller chunks before embedding.
Typical chunk configuration:
- Chunk size: 300–800 tokens
- Overlap: 10–20%
Chunking improves retrieval accuracy and avoids context overflow.
Embedding Model
Each text chunk is converted into a numerical vector.
Popular embedding models include:
- OpenAI text-embedding-3-large
- BGE-large
- Instructor-XL
- E5 embeddings
- MiniLM
Example vector representation:
[0.021, -0.44, 0.91, ...]
Vector Database
A vector database stores embeddings and metadata.
Common vector databases:
- FAISS
- ChromaDB
- Pinecone
- Weaviate
- Milvus
- Qdrant
These databases enable semantic similarity search.
Retriever
The retriever is responsible for:
- Embedding the user query
- Searching similar vectors
- Returning top-K relevant chunks
Retrieval quality directly impacts answer accuracy.
Prompt Construction
Retrieved chunks are injected into the prompt.
Example:
Answer the question using only the context below.
If the answer is not found, respond with "Not available".
<context>
...
</context>
Large Language Model
The LLM generates the final response using the retrieved context.
Examples include:
- GPT-4
- Claude
- Llama 3
- Mistral
- Mixtral
Complete RAG Data Flow
Documents → Chunk → Embed → Vector Database
↑
User Query → Embed → Retrieve ────┘
↓
Prompt + Context
↓
LLM
↓
Answer
Algorithms Commonly Used in RAG
Dense Vector Similarity Search
This is the most widely used retrieval algorithm in RAG.
Similarity methods include:
- Cosine similarity
- Dot product
- Euclidean distance
It enables semantic matching instead of keyword matching.
Approximate Nearest Neighbor (ANN)
ANN algorithms make vector search scalable.
Common ANN techniques:
- HNSW
- IVF
- ScaNN
Used internally by most vector databases for fast retrieval.
BM25 Algorithm
BM25 is a traditional keyword-based retrieval algorithm.
Strengths:
- Excellent exact-match precision
- Works well with numbers and identifiers
Limitations:
- No semantic understanding
Hybrid Search
Hybrid search combines:
- BM25 keyword search
- Dense vector similarity
Final ranking is calculated using weighted scores.
Hybrid search is widely used in enterprise RAG systems.
Re-Ranking Algorithms
Re-ranking improves retrieval quality after initial search.
Popular approaches:
- Cross-encoders
- BGE re-ranker
- Cohere re-ranker
- ColBERT
Flow:
Retrieve top 20 → re-rank → select top 5
Multi-Query Retrieval
The LLM generates multiple variations of the user query.
Each variation retrieves documents independently.
Results are merged to improve recall.
Parent-Child Chunking
Documents are divided into:
- Parent chunks (large context)
- Child chunks (search units)
Retrieval happens on child chunks while the parent context is sent to the LLM.
Self-Query Retrieval
The LLM extracts metadata filters from the question.
Example:
"Show finance reports from 2024"
→ year = 2024
→ category = finance
Structured filtering improves precision.
When to Use RAG
RAG is ideal when:
- Data is private or proprietary
- Information changes frequently
- Answers must be factual
- Hallucination must be minimized
- Fine-tuning is not practical
Final Thoughts
RAG is not a tool or framework.
It is an architectural pattern that combines:
- Information retrieval
- Vector search
- Prompt engineering
- Language generation
The effectiveness of a RAG system depends more on retrieval quality than on the LLM itself.
Understanding RAG architecture and its algorithms is essential for every AI engineer.