Why Vector Databases Matter for RAG?
Fri Jan 09 2026
📚 Vector Search Demystified
Retrieval-Augmented Generation (RAG) is quickly becoming a core technique behind many modern AI applications — from chatbots and knowledge assistants to enterprise search tools.
But for RAG to work well and return accurate answers, it relies heavily on one key component:
👉 Vector Databases
This post explains what they are, why they matter, and how they power RAG, in a simple, beginner-friendly way.
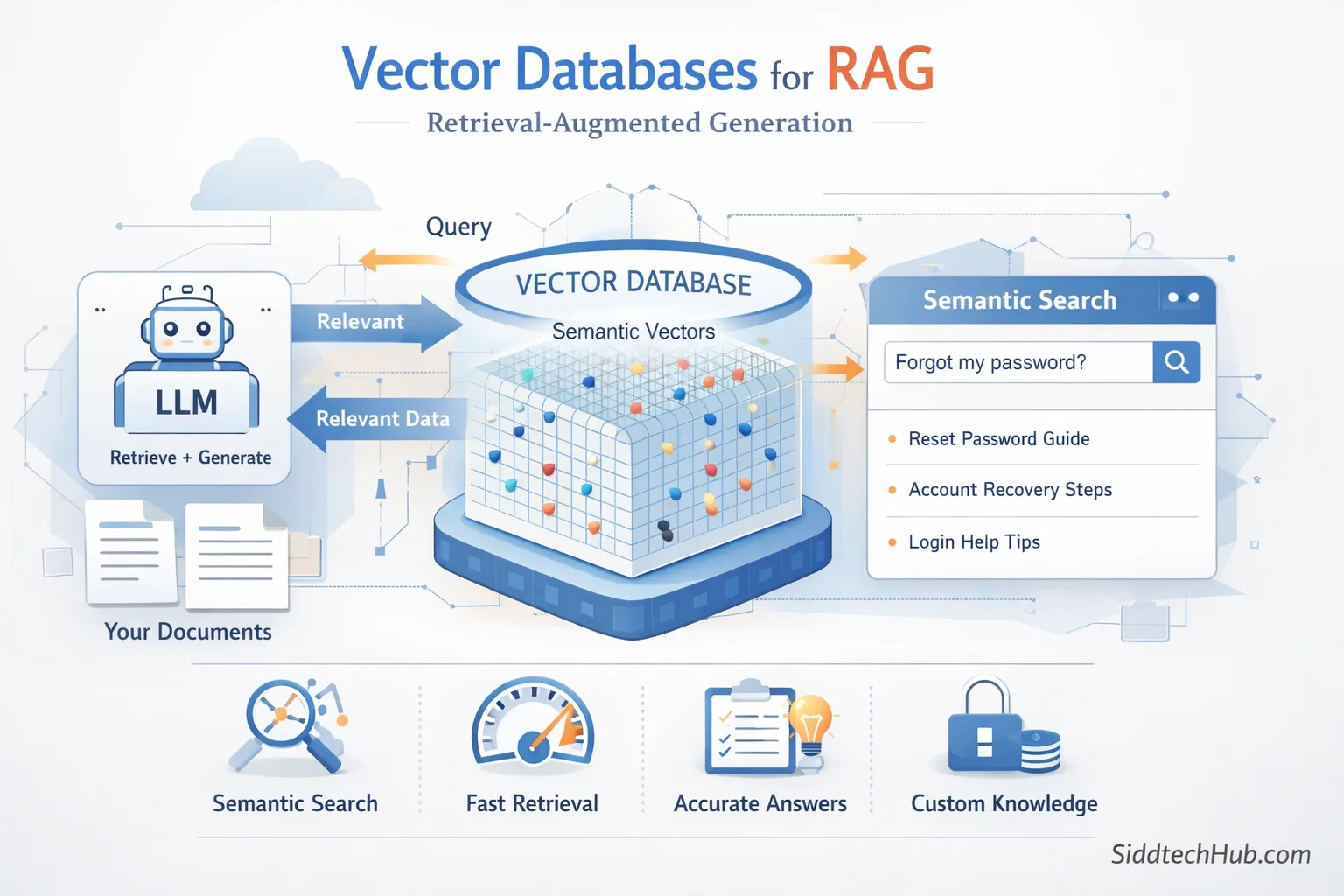
🤖 What is RAG?
RAG stands for Retrieval-Augmented Generation.
Instead of depending solely on what a large language model already knows, RAG works in two steps:
- Retrieve: Pull relevant information from your own data sources
- Augment & Generate: Feed those details to the model to produce a more accurate answer
This makes AI:
- More factual
- More current
- More trustworthy
🧠 Why You Need Vector Databases in RAG
Traditional databases store text and retrieve results using keywords.
Vector databases store embeddings - numerical representations of meaning.
This means a vector database:
- Understands semantic similarity
- Doesn’t require exact keyword matches
- Retrieves conceptually relevant information
Example:
Query: "How do I get back into my account?"
A keyword search may miss results that don’t include “account”
A vector search finds instructions about password reset, login recovery, etc.
⭐ Benefits of Vector Databases for RAG
1️⃣ Semantic Search, Not Keyword Guessing
They return content based on meaning, not just matching words.
2️⃣ High-Speed Retrieval at Scale
Whether storing hundreds or millions of documents, search stays fast.
3️⃣ Better Final Answers
RAG depends on the quality of retrieved context — vectors provide accuracy.
4️⃣ No Model Retraining Required
Simply embed new data and store it — your system learns instantly.
5️⃣ Secure and Custom Knowledge
You control the data the AI uses — ideal for enterprise and private use cases.
🛠️ Mini Example — Vector Search in Python
Below is a tiny RAG-style demo using FAISS:
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
# 1. Load the embedding model
model = SentenceTransformer('all-MiniLM-L6-v2')
# 2. Create sample documents
docs = [
"Reset your password from the account settings page.",
"You can contact support for billing queries.",
"Two-factor authentication keeps your account secure."
]
# 3. Convert documents to vectors
doc_vectors = model.encode(docs)
# 4. Build an index with FAISS
index = faiss.IndexFlatL2(doc_vectors.shape[1])
index.add(np.array(doc_vectors))
# 5. Ask a question
query = "I forgot my password, what do I do?"
query_vec = model.encode([query])
# 6. Retrieve closest match
distance, idx = index.search(query_vec, 1)
print("Query:", query)
print("Best match:", docs[idx[0][0]])
Expected result:
Reset your password from the account settings page.
—even though the question did not use the word reset.
🧩 Final Takeaway
Vector databases are the engine behind RAG systems.
They:
- Enable semantic, meaningful search
- Improve accuracy
- Scale effortlessly
- Work with private datasets
- Make AI feel smarter and more useful